A long (long) time ago I wrote an essay on Frequency Separation, even if the main subject was disguised in the more approachable title “Notes on Sharpening”. That was early 2009, way before Frequency Separation was cool, then popularized/mainstream, then possibly cool again. I’ve thought to revisit the original article to give the subject a new coat of 2021 paint, plus all sorts of new detours.
Spoiler alert: I’m interested in Frequency Separation as a tool for a broader set of manipulations not limited to, nor particularly focused on, beauty/skin retouch.
1. Frequencies
I assume that you already know what we’re talking about, TL;DR any signal, e.g. a sound wave no matter how complex can be built composing “pure” frequencies.
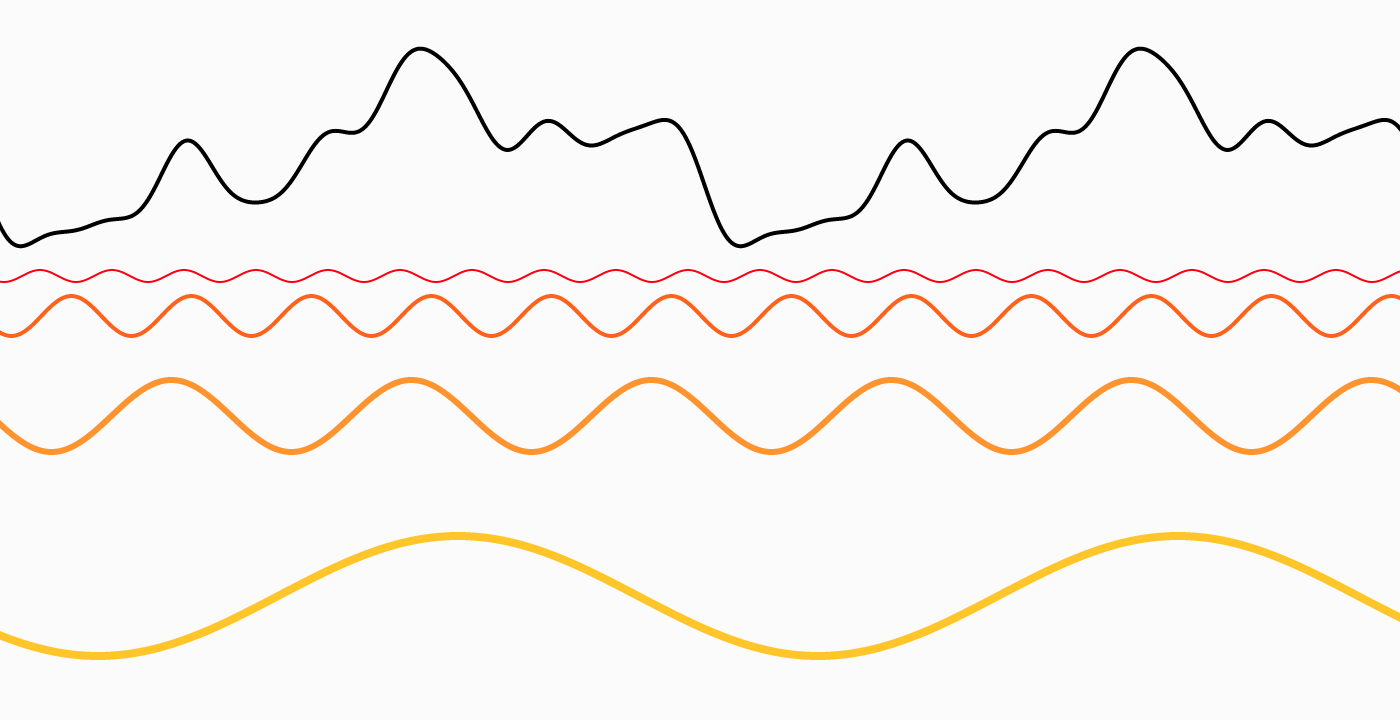
Low frequencies are at the bottom, high on top, black is the result. If you want to understand the concept better, this article goes in much more detail and will blow your mind too.
In the more familiar realm of images, you can think of high frequencies as describing thin detail (given a defined area, a lot of stuff happens there), while low frequencies are in charge of spatially slower changes:
2. Basic frequency separation
As opposed to the signal wave example, with images we usually deal with frequency ranges. When you filter with Gaussian Blur (Filter > Blur > Gaussian Blur, GB from now on) e.g. radius 10px, you’re getting rid of all the high frequencies (i.e. detail) that belong to the smaller-than-10px range. Whereas if you High-Pass (Filter > Others > High Pass, HP from now on) with the same radius you’re doing the opposite: you’re left with everything that belongs to the smaller-than-10px range (only the high frequencies are allowed to pass – hence the filter name).

I’ve picked this image for most of the examples – it’s a 1887 painting by Abbott Handerson Thayer, a portrait of his daughter from the Smithsonian Institute collection.
In the early days we used to combine the GB and HP layers (the latter in Linear Light blending mode, 50% opacity) but that’s not really precise enough for our purposes here. There are two ways to deal with a proper frequency decomposition, depending on whether the file is 16bit or 8bit.
- Duplicate the original (O) twice, and call the two new layers L (low) and H (high).
- Place H above L, hide H and select L.
- Apply GB to L, with a radius large enough so that the detail that you want to migrate to the other layer disappears.
- Select H, then Image > Apply Image with the following settings
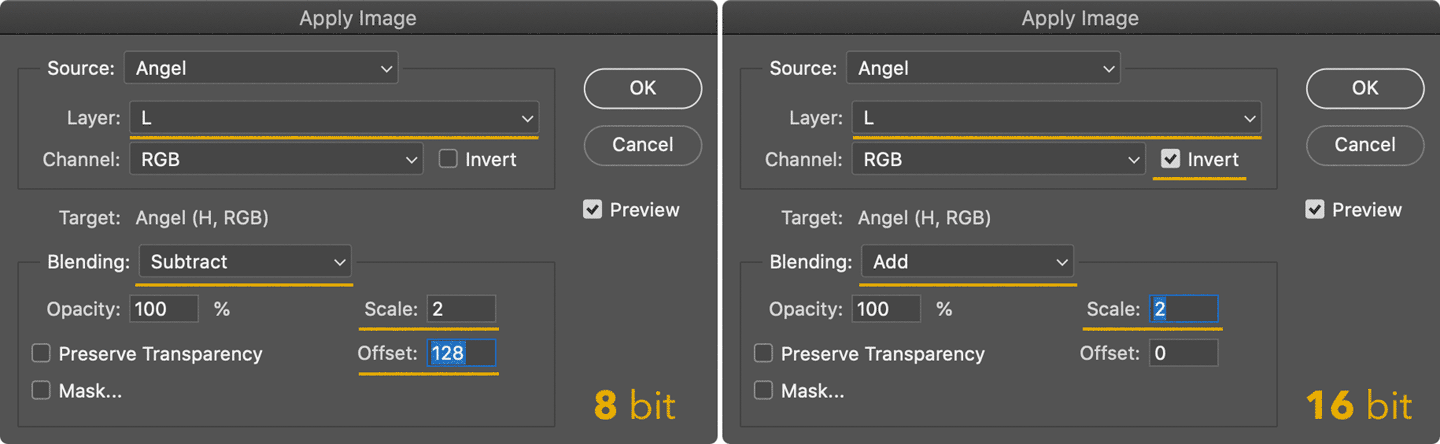
- Change the H blending mode to Linear Light (LL from now on)
- Optionally, clip H to the L layer (Alt or Option click the line in between the L and H layers in the Layers palette)
You should end up with this simple setup:

That is to say: the original layer, and the same built with a Low + High frequency decomposition. They are 100% identical, but why? And also, why different Apply Image settings for 8/16bit? That’s not been discussed very much (if at all): to properly understand we need to get into blending modes maths.
3. Blending Modes maths
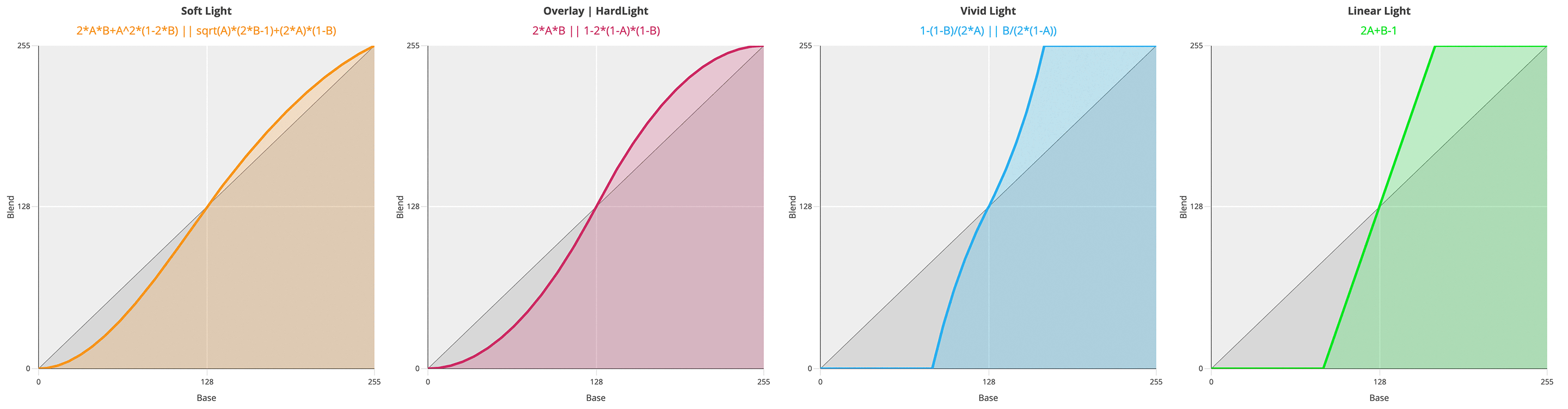
Blending modes are arbitrary ways to mix two layers – say a Base (B) below and an Active (A) above – according to a formula.
Some blends are easier to understand if applied on normalized values, i.e. in the range (0,1). As an example, Multiply is a well known darkening blending mode, but not if the multiplication is calculated with pixel values in the (0,255) range. Let’s pretend that we have the following values1.
\[\require{cancel} A = 51 \\ B = 153 \\ A * B = 51 * 153 = 7.803\]A brightened result, that must be normalized with a 255 factor to be meaningful and appear darkened:
\[\frac{51 * 153}{255} = 30.6\]If you normalize them first it’s just the same
\[A = \frac{51}{255} = 0.2 \\ B = \frac{153}{255} = 0.6 \\ A * B = 0.2 * 0.6 = 0.12 \\ 0.12 * 255 = 30.6\]When the result is out of scale it’s clipped to 0 or 255, unless further blends are to be calculated.
Various online sources state that Linear Light is a mix of Linear Dodge (Add) and Linear Burn. Is it really? (Spoiler alert: nope) Let’s test it. With Linear Dodge (Add), the formula for the blend is (A + B). Being a simple addition, you can use both the normalized (0,1) or the (0,255) range: it makes no difference. Using the same values for A, B from the previous example:
\[A + B = 0.2 + 0.6 = 0.8 \\ 0.8 * 255 = 204 \\ A + B = 51 + 153 = 204\]The Linear Burn formula is A + B - 1: an addition follwed by an inversion (white is subtracted).
\[A + B - 1 = 0.2 + 0.6 - 1 = -0.2 \\ A + B - 1 = 51 + 153 - 255 = -51\]Negative values are clipped to zero. Let me stress that “inversion” here means “subtraction with white”, which is 1 in the normalized range, and should be 255 for 8bit documents (more on that later).
The Linear Light formula is instead 2A + B - 1, so twice the impact for the top layer. If you draw a gradient from Black to White on a new document, duplicate the layer and change its blend mode, these are the result for Linear Dodge/Burn/Light:
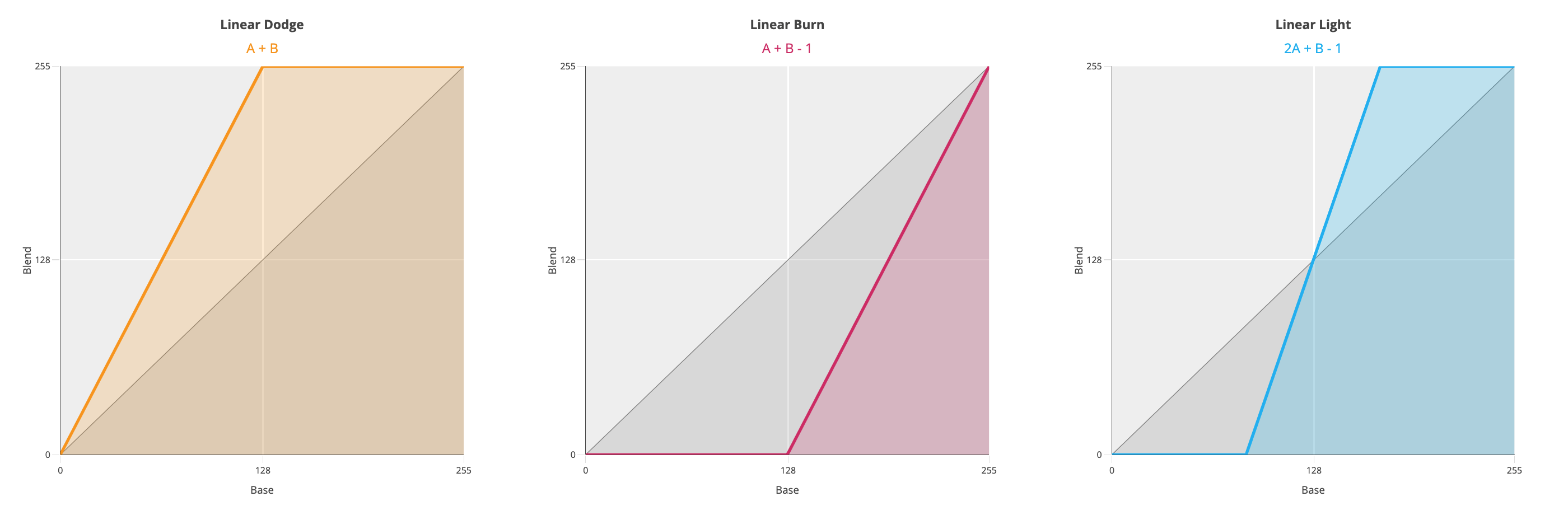
So I’m afraid no, LinearLight is not “a combination of Linear Dodge and Linear Burn” because the slope of the curve is different. It’s not a shift of either formulas (resulting in A + B - 0.5), which would have in fact pivoted the line around (0.5, 0.5). With Linear Light the slope is steeper – and in fact the formula is 2A + B -1.
Now that we’ve got this, let’s try to understand why Linear Light works with the kind of Apply Image that we’ve used. There’s nothing inherently “frequency separation-y” with Linear Light, it just happens to combine perfectly with the sort of Image Calculations we’ve performed. We’ll start with the 8bit version, and move to the 16bit next.
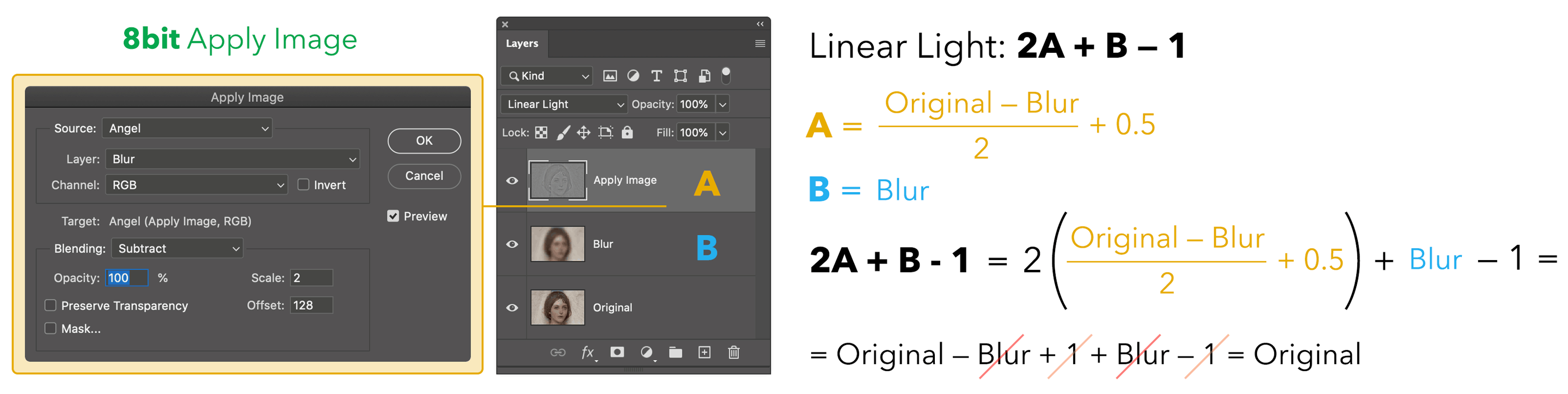
The Apply Image step was the Original minus the Blurred (hence the Subtract mode) with Scale 2 (meaning divided by 2) and Offset (i.e. plus) 128 that is normalized to 0.5. All this is equal to the grayish detail layer, which is then set to Linear Light blending mode: being on top, let’s call it A. The layer below (B) is the Original, and the blend formula for Linear Light is 2A + B - 1. Let’s substitute A with (Original - Blur)/2 + 0.5 in the formula and you see that everything simplifies to Original, QED.
In other words, we’ve demonstrated why this particular Subtraction (with Scale 2, Offset 128) perfectly combines with the Linear Light blending mode to return an identical copy of the original. Cool!
Let’s see how the theory works with 16 bit files and its different Apply Image.
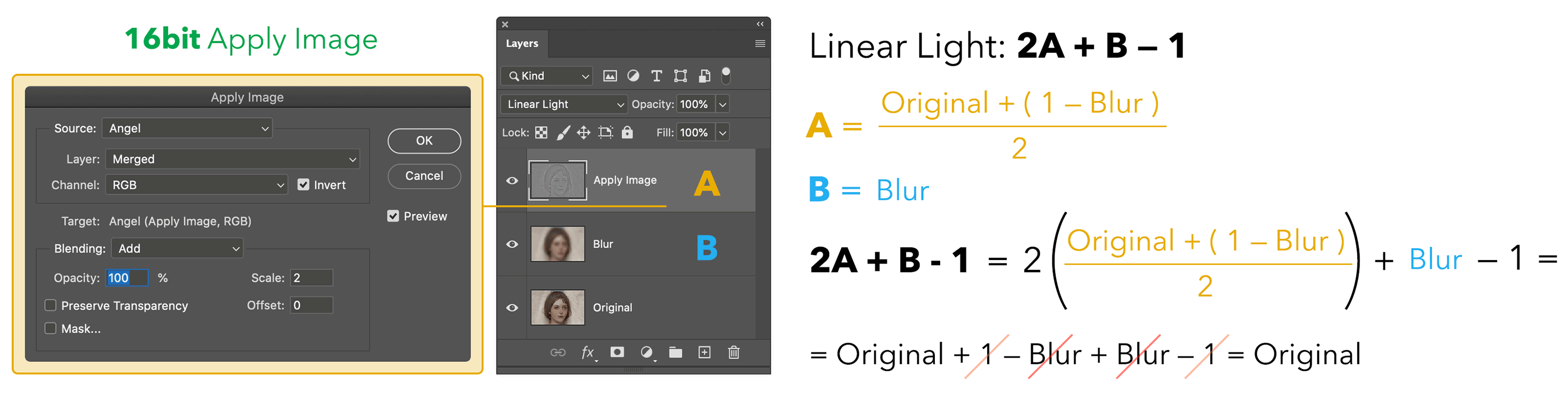
Here we’re Adding to the Original the inverted Blurred (hence 1 minus Blurred, this is how you invert pixels), scaling 2 (i.e. divided by 2). This is again the detail layer then set to Linear Light mode: we call this A, and B is the Original. Applying the same blending formula 2A + B - 1 we can substitute A in it and everything simplifies to the Original. Great!
So it’s not that Linear Light is a magic blend mode, nor that it fits Frequency Separation. The Apply Image settings happen to work with Linear Light in returning the original values.
Then… why two different methods with 8bit/16bit documents? You’re ready for some bit depth Maths.
4. 8bit vs. 16bit Maths
For 8bit images, pixel values are in 2^8 = 256 range, i.e. (0,255). Black is zero, White is two-hundred-fifty-five. You might be tempted to assume that 16bit works the same, but it turns out that Adobe Photoshop’s 16bit is in fact 15bit + 1, meaning 2^15 + 1 = 32768 + 1 = 32769, expressed in the range (0,32768). Why? The accepted answer is that “this gives a midpoint to the range (very useful for blending), and allows for faster math because we can use bit shifts instead of divides” (source).
4.1 8bit special inversion
I’ve tried to reverse engineer the way Photoshop handles pixel calculations, and there is something interesting going on here. Let’s create a dummy test document, 8bit.
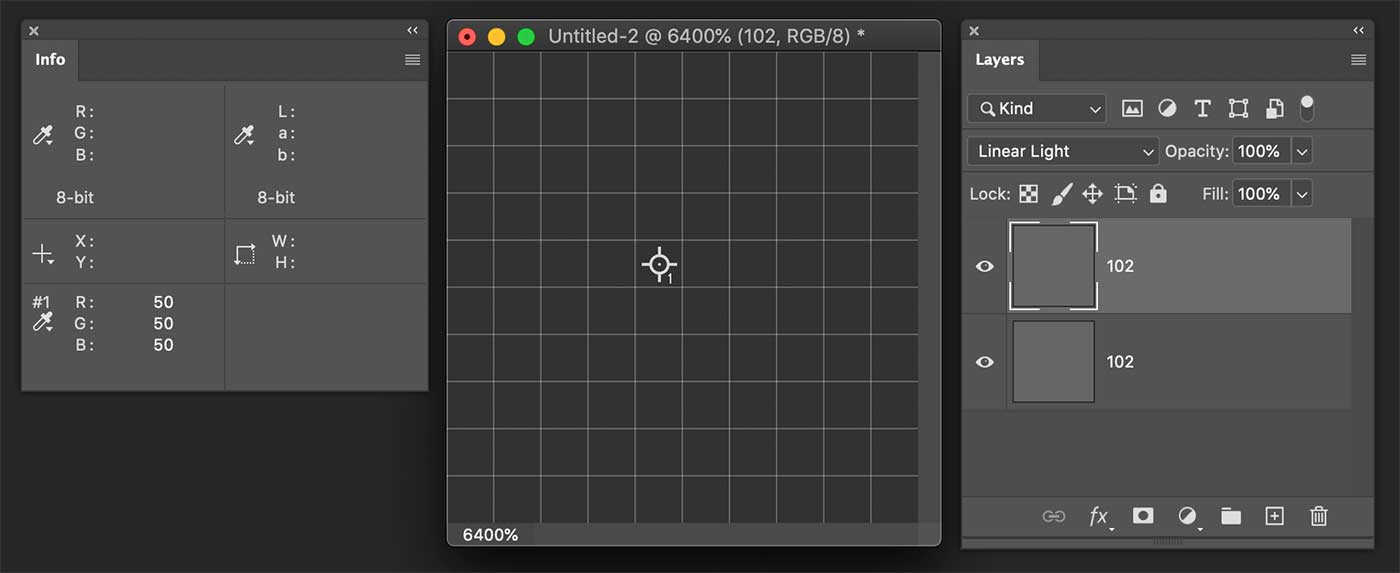
As you see I’ve created two layers, solid 102,102,102. When the topmost is in Linear Light I would expect the blend to be 2A + B - 1, where 1 is the highest value possible in the (0,255) 8bit range, that is to say White: 255. Hence the formula would give:
\[LL = 2A + B - 1 = 2 * 102 + 102 - 255 = 51\]Alas, “computer says no”, and PS calculates 50. There are no divisions here, so I wouldn’t expect rounding errors of any sort, it’s quite straightforward. I’ve tested it with a bunch of different pixel values for the top and bottom layers, and the result is always off by 1.
Out of curiosity I’ve tested Affinity Photo and it works as I’d expect:
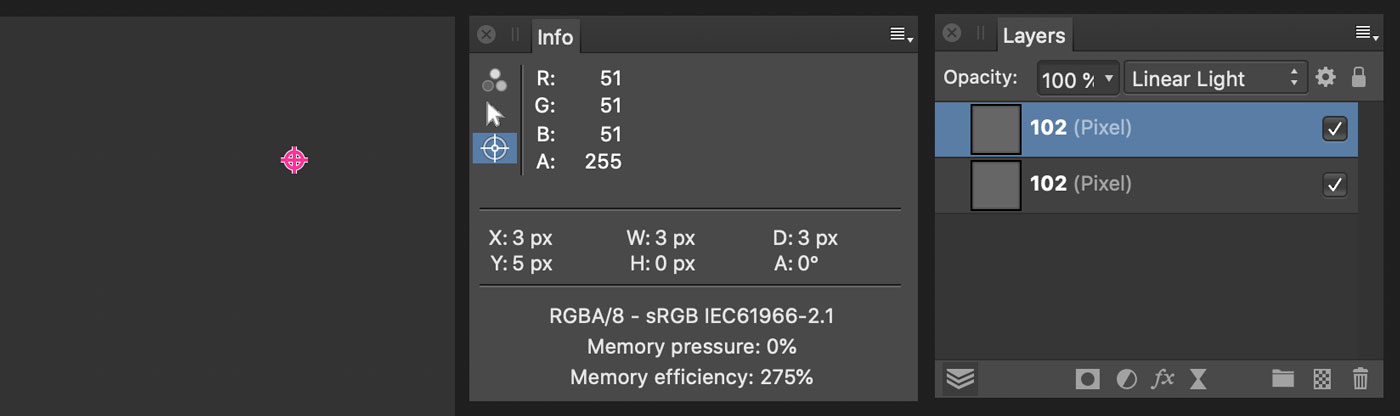
The only explanation is that Photoshop subtracts 256 instead of 255. This is in fact the case, and the reason is that otherwise there would be no neutral color in Linear Light with 8bit documents.
\[LL = 2A + B - 1\]A is the layer above, the one which middle gray is meant to be “neutral” (have no effect) in the blend. Let’s rewrite it as:
\[LL = B + (2A - 1) \\ LL = B + \Delta A\]Where:
\[\Delta A = 2A - 1\]There must be a value of A (the neutral, mid-gray) such that deltaA is equal to zero. But using 255 as the white, zero is nowhere to be found.
\[A = 128 \\ \Delta A = 2 * 128 - 255 = 1\] \[A = 127 \\ \Delta A = 2 * 127 - 255 = -1\]Instead, if you subtract 256 the neutral value happens to be 128, which is in fact the proper mid-gray value in use:
\[A = 128 \\ \Delta A = 2 * 128 - 256 = 0\]This is true for 8bit documents only.
For 16bit documents, given their particular nature of 15bit + 1, there are 32769 values in the (0, 32768) range, hence no need to tweak the white subtraction. In fact, the used value is the proper 32768.
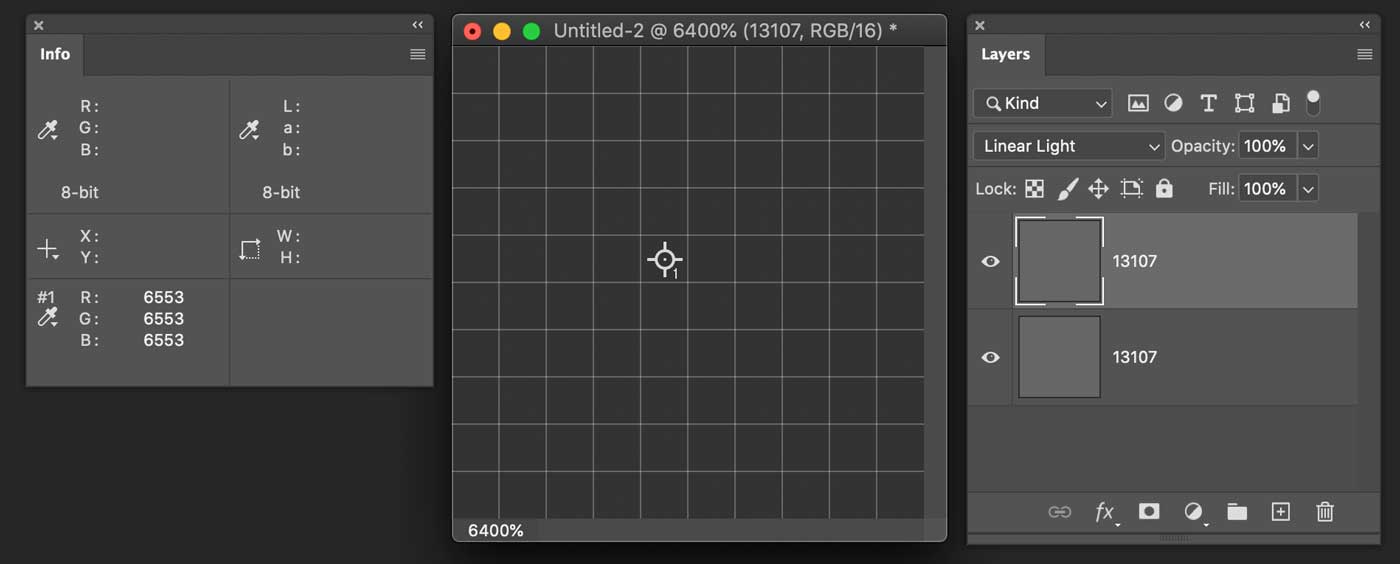
4.2 Image Calculations: 8bit
I’ve created an edge and noted the pixel values for the Original layer that you can see either in the Info palette for the two color samplers and in the layer name as well. I’ve also added a Blurred (2px radius) layer – trust me the color sampler values are ones in the Layers palette.

Let’s crank some numbers and see if we’re able to calculate the Apply Image value.
Please note this is an 8bit file, so let’s start with the recommended calculation, a Subtraction with Scale 2 and Offset 128.
\[O = 153 \\ GB = 112\] \[Apply Image = \frac{O - GB}{2} + 128 = \frac{153 - 112}{2} + 128 = \frac{41}{2} + 128\]Let me pause for a moment: 41/2 here is equal to 20, for there’s no such a thing as 20.5 in the integers (0,255) range – more on rounding in a minute.
\[Apply Image = 20 + 128 = 148\]Which is exactly the correct value that Photoshop comes up with:

A quick check for the darker values too:
\[O = 51 \\ GB = 92\] \[Apply Image = \frac{51 - 92}{2} + 128 = \frac{-41}{2} + 128 = -20 + 128 = 108\]Which is exactly what you can see in the Info palette above. We’ve confirmed the Apply Image result.
Now it’s kinda easy, we need to apply the Linear Light formula (2A + B - 1), where A is the value we’ve calculated, B is the Blurred, and 1 is the “special” white that Adobe uses for 8bit Linear Light, i.e. 256.
Lighter values on the left:
\[LL = 2 * 148 + 112 - 256 = 152\]Darker values on the right:
\[LL = 2 * 108 + 92 - 256 = 52\]Photoshop confirms:

So we’re off one point in both dark and light side. I’ve noted all the values along the 10 pixels the image is wide:
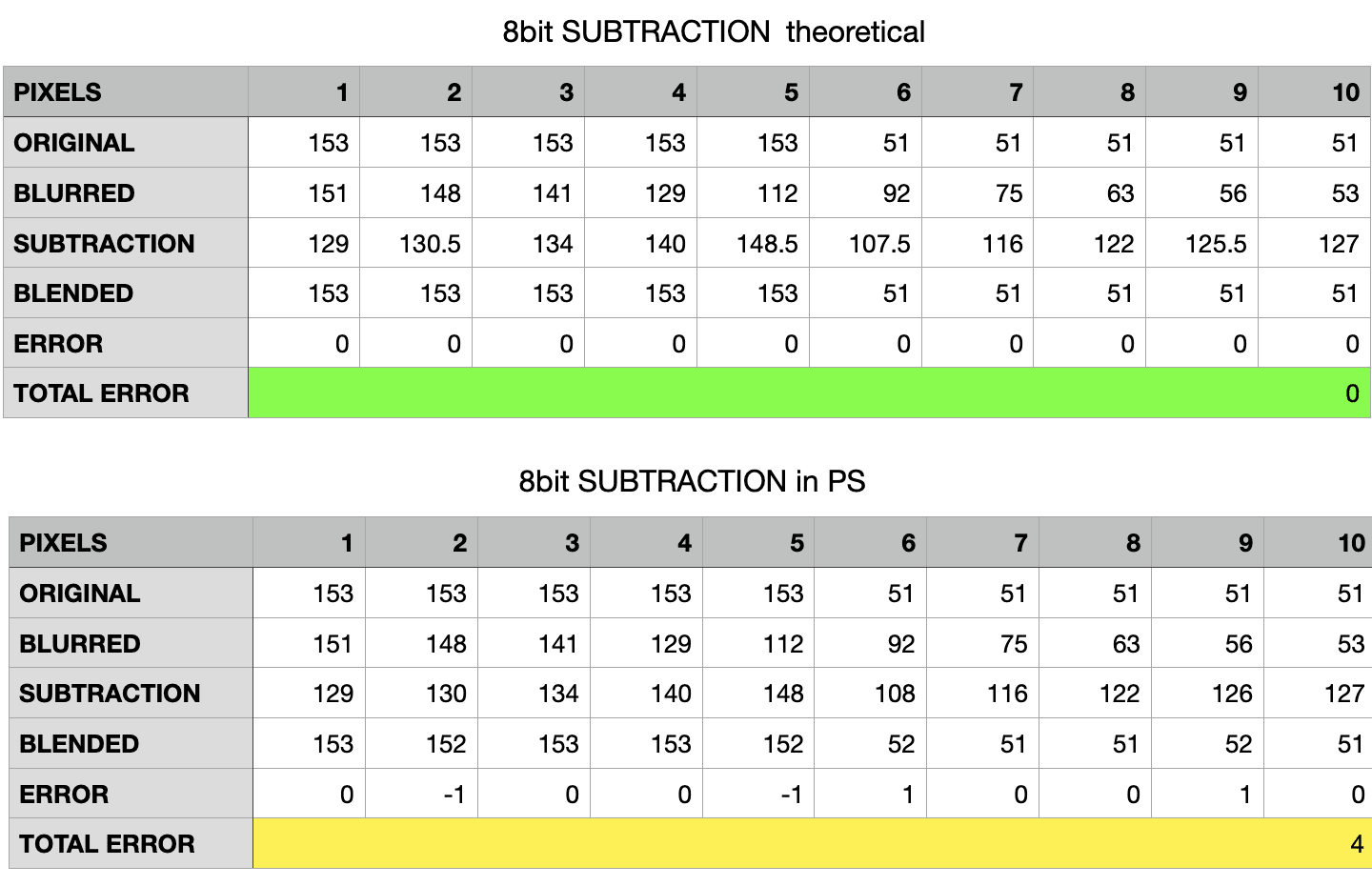
Why two different tables? Because Photoshop rounds values to the integer in an inconsistent way – or at least in a way for which I haven’t been able to find the rule. The table above shows the “theoretical values” (floats, which would lead to zero errors everywhere), while the bottom one is filled with the actual readings. I say PS rounds inconsistently because for reasons unknown to me the first five values in the Subtraction row are rounded down (130.5 $ \to $ 130, the floor), while the last five values are rounded up (125.5 $ \to $ 126, the ceiling). Go figure.
All in all, for 10 pixels we’ve got 4 off by 1 (in absolute value), so a total error of 4.
Let’s try with the same 8bit document, but with the 16bit Calculations instead (the Addition of the inverted, Scaled 2)
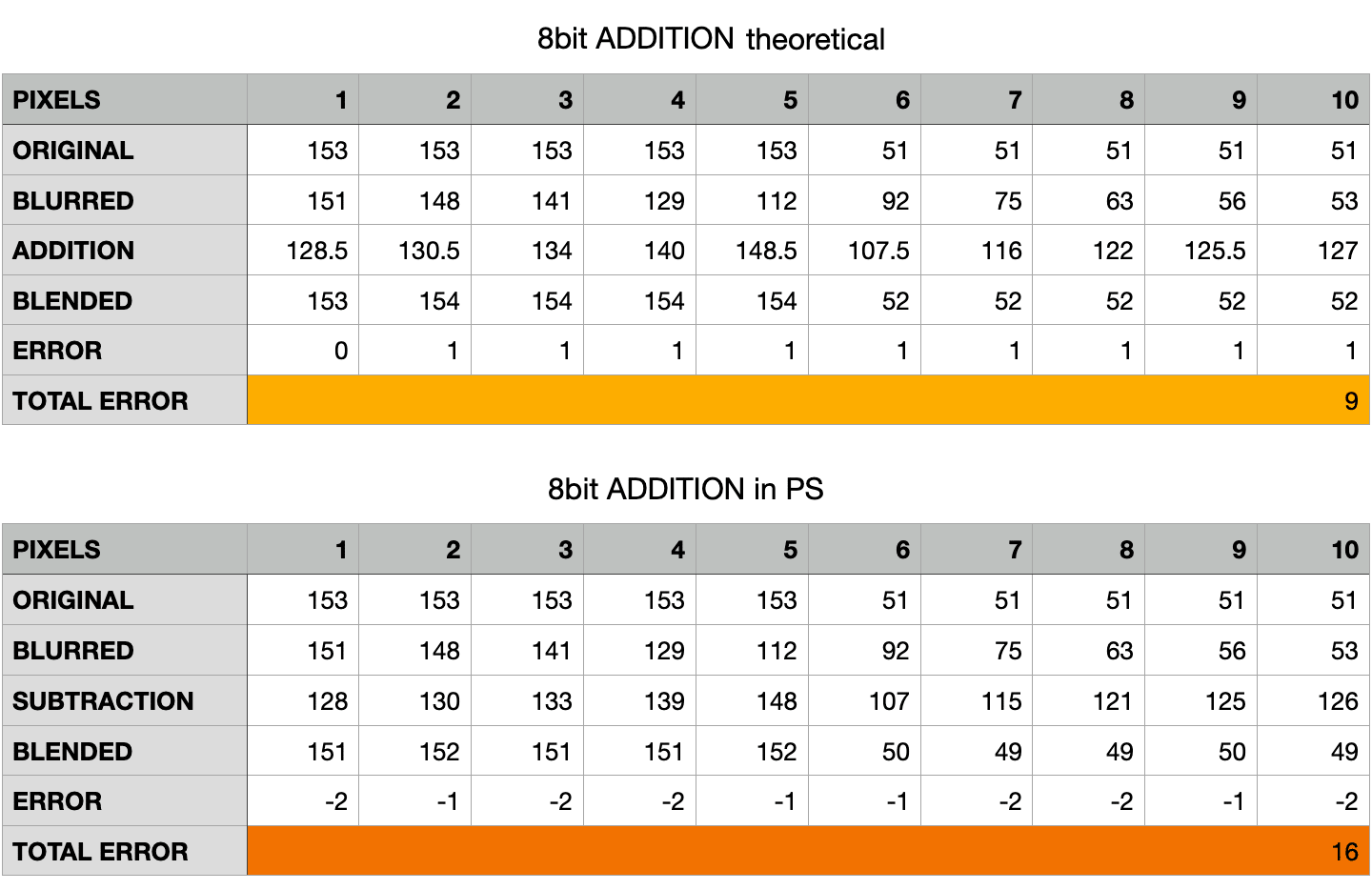
The results are much worse. On the one hand there are the same weird behaviour mixing ceiling and floor rounding. On the other hand, the theoretical error is more than twice the real error for the Subtraction calculation, and 4 times that in the actual document!
Even when rounding is not needed (e.g. for pixels 3, 4, 7, 8, 10) the theoretical value is always off by 1. My understanding is that the special white value (256 instead of 255) used in the LL blend is compensated with the 128 offset in the Subtraction method only. Why some values are even worse in the actual readings (same pixels 3, 4, 7, 8, 10) I have no explanation for. But the experimental result is that Addition in an 8bit file results in a greater error, 4 times the Subtraction’s.
4.3 Image Calculations: 16bit
I’ve set up a similar document, but 16bit (with the sampler set to read 16bit values):

Let me show you the spreadsheets for the recommended 16bit calculation, Addition of the inverse, Scaled 2
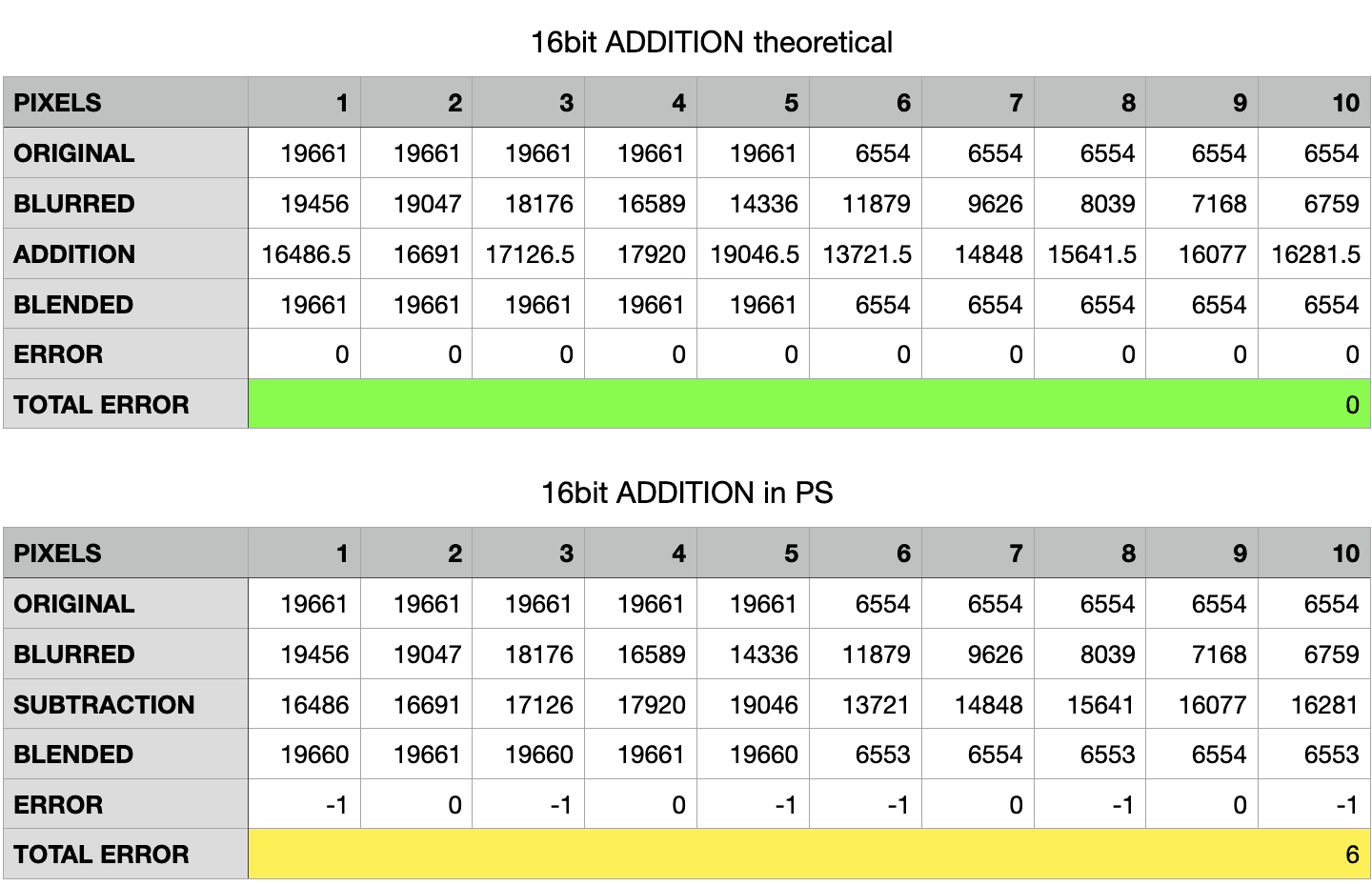
Here the theoretical error is always zero, whereas the actual document shows minimal deviation. Different story if you try the recommended Apply Image settings for 8bit, the Subtraction with Scale 2 and 128 Offset:
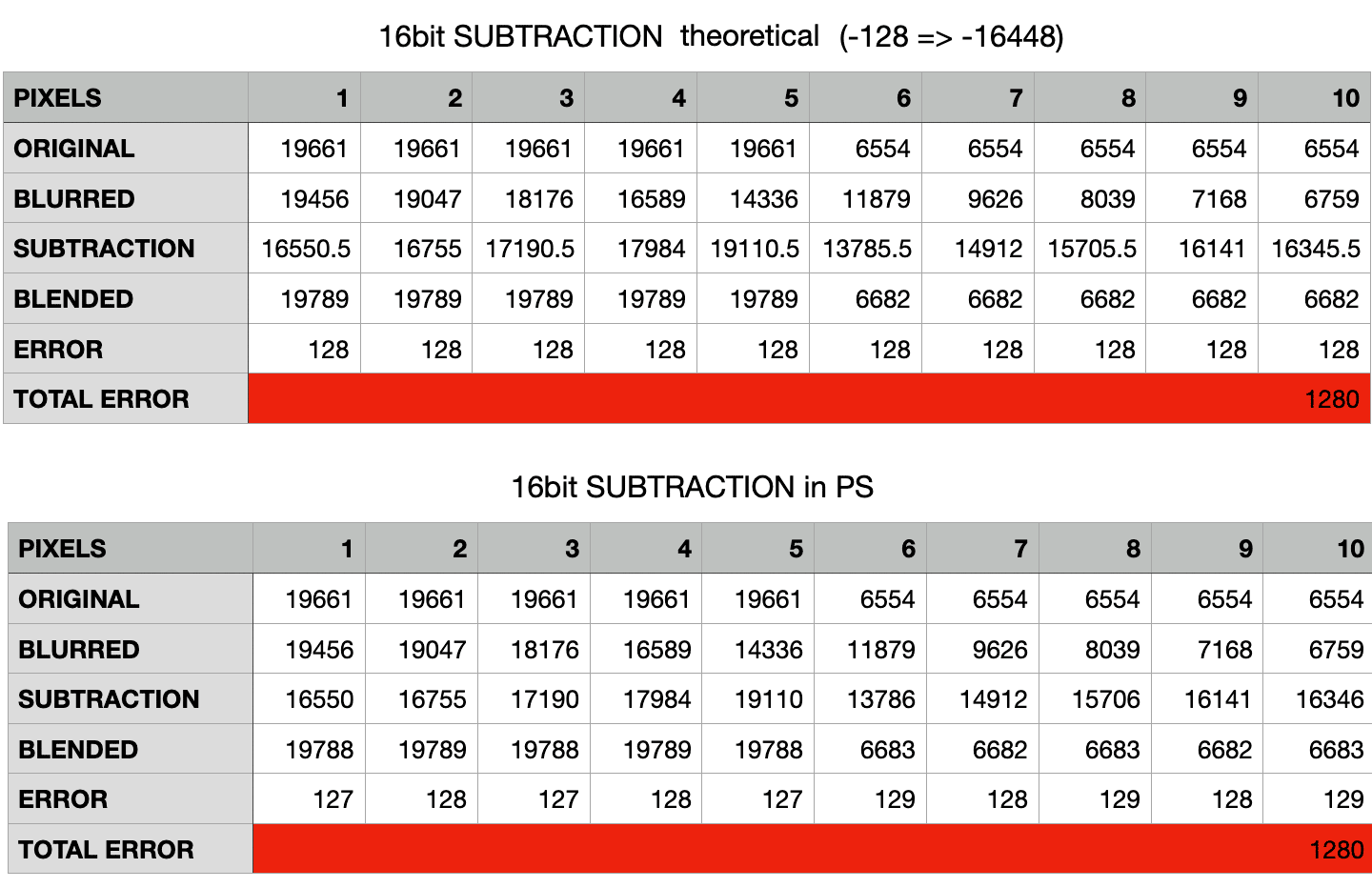
Here the error is much greater: I’d say due to the fact that 128 translates (in 16bit) to 16448. Try adding a 128 solid color layer and measure it in Photoshop with the color sampler set to 16bit, this is the value you’re going to get. My interpretation of the experimental results is that the difference is due to the mismatch between the theoretical middle-gray offset for 16bit documents (16384) and the one used in Apply Image (16448) – where you have to enter an 8bit number even if the document is 16bit.
Mind you: 1280 seems to be a much bigger error than the 16 points of the 8bit Addition case, but it’s actually lower: it’s a 4% error, compared to 6% of the 8bit.
Fun fact: in 16bit documents, it seems that rounding is always floor in the Addition, ceiling in the Subtraction.
There still are some points for which I haven’t a proper explanation:
- Why there are differences between theoretical and actual readings even with non rounded values.
- How can PS rounds using both floor or ceiling values for x.5 numbers.
All in all, the above experiment proves that no method hits the bull’s eye but the measured errors are smaller when using Subtraction with Scale 2 and 128 Offset on 8bit documents and Addition of the inverse with Scale 2 on 16bit documents.
4.4 High Pass
Before going any further, let me point out that the High Pass filter doesn’t output the same Detail layer as the decomposition we’ve performed.

On the left you see the Detail layer, center the High Pass with same radius as the Gaussian Blur (much stronger effect). Right, putting the HP layer half opacity on top of a mid-gray layer (Edit > Fill > 50% Gray). Apparently it’s now identical: if you put the HP on top of the Detail, Difference blending mode, the result is full black and both Mean and Std Deviation (from the Histogram palette) are equal to zero. This for a 16bit file, while an 8bit file shows 0.50. In both cases, an extreme contrasting curve shows noise, which in the 16bit case might be just rounding errors (not so sure about the 8bit one).
All in all, I will keep using the Apply Image method, especially when decomposing the image for retouching purposes.
5. Single Kernels
In my experience, Photoshop people tend to think about Frequency Separation mainly as a retouching tool. Sure the image decomposition helps targeting the retouching process in ways and with such precision/ease that would be otherwise impossible, but I am personally also interested in contrast enhancements.
5.1 Gaussian kernel
As soon as you’re able to separate frequency ranges into their own layers, they can be successfully used to enhance or dampen those features in the original image. Gaussian Sharpening is a classic example: without entering the details of the three parameters of the UnSharpMask filter here, conceptually it’s just a matter of creating a Gaussian separation and adding the frequencies back to the original – basically discarding the Blurred layer and using the Detail one only. Exaggerated radius (40px) demonstration as follows.
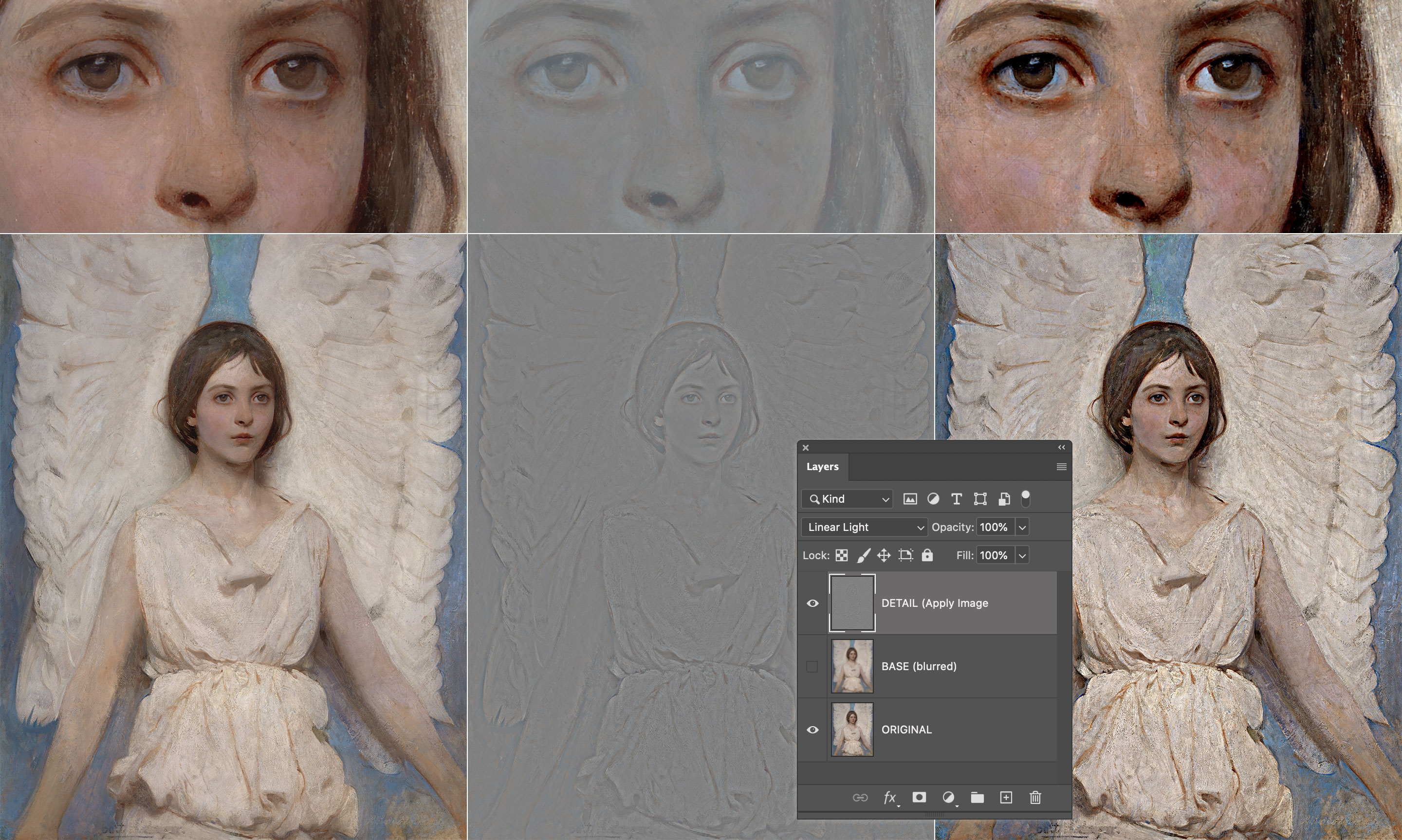
Several things to point out ASAP.
- First, a “Gaussian separation” means a Frequency Separation that uses the Gaussian Blur filter. As we’ll see in a short while, we’re not limited to that at all.
- Second, “adding back” is a loose term that means putting the Detail layer (the one that’s the result of the Apply Image step) into Linear Light blending mode directly on top of the Original, discarding the Base (blurred) layer.
- Third, as soon as we enter the realm of contrast enhancement we can leave the rigorous math we needed for the decomposition behind. In the image above I’ve used Linear Light at full opacity. You can experiment lowering the opacity or using different contrast blending modes2.
- Fourth, due to the fact that Apply Image and the Linear Light blend work on a per channel basis, as a result the color is expected to be saturated and the hue sometimes shifted. The effect may be welcome or may be not. Without the need to bother with a Merge Layer on top switched then to Luminosity blending mode, you can force the Luminosity only by clipping the Detail layer to whatever blank/zeroed Adjustment Layer you want, provided that the latter (only) is set in Luminosity, while the Detail layer is whatever contrast blending mode you like.

This is a little known technique that lets you mix blending modes in a very fast and cheap (in terms of filesize) way.
Alternatively, you can slightly tweak the procedure. If after the Gaussian Blur you Edit > Fade Gaussian Blur… and set it to “Luminosity” you end up with a weird looking blurred thing.

When using that one for the Image Apply step, then the resulting Detail layer is completely desaturated, hence the result when applying it back to the original has the same effect as retaining only the Luminosity part.
It’s quite important that you understand how the above works. We’ve subtracted a Blurred version from the Original, in order to get the gray-blob that I’ve called the Detail layer.
\[D = O - GB\]Where D is Detail, O is Original, and GB stands for Gaussian Blur (the blurred layer). If the GB is blurred in the Luminosity only, then:
\[D_{lum} = O - GB_{lum}\]Finally, nothing prevents you to use the regular decomposition and retain the color only, in order to emphasize a more impressionistic effect – some sort of Michel Eugène Chevreul influenced simultaneous contrast boosted look.

Feel free to mix different amounts of Color and Luminosity for greater control. Also note that if you invert the Detail layer you get the opposite effect: dampening that frequency range rather than enhancing them. It’s of little use with a Gaussian kernel (a decomposition which is based on a Gaussian Blur filter) because it would just return a blurred version:

But with other kernels (especially mixed ones) and varying the opacity it can lead to very interesting results.
5.2 Non-Gaussian kernels
There’s nothing special in the Gaussian Blur filter when it comes to image decomposition as we’ve seen it so far. Provided that you subtract3 the Original with the “processed” version and you put the result on top of the filtered in Linear Light, you’re going to get the Original back. You can try silly filters if you want:

You can even throw in something totally unrelated and it’ll work all the same.

Think about the Apply Image step like noise cancelling headphones: you’re somehow factoring out the “interference” (the altered image) and find a signal that, combined with it, returns the frequencies you want to hear. All those weird filters have no use, but to help you get the point.
At this point you should have built the intuition that what the kind of detail that the kernel destroys, is the kind of stuff that migrates in the Detail layer and you’ll be able to enhance/retouch in the original image. One well-known kernel used in such decompositions is the Bilateral Filter, a.k.a. the Surface Blur. Killing (in theory) everything but edges, you can expect that it’s going to enhance Textures and leave Edges more or less alone.

The result is not meant to be pretty here: it illustrates the point, and it’s yet another item in your toolbox to grab when the right image comes along. Please remember that these two-layers decompositions can be used for retouching purposes with a Base (blurred) + Detail layer, so it can be interesting, depending on the image, to be able to target fine textures and leave edges alone.
Another quite common kernel is the Median, mostly because it suits retouchers when they need to address the Detail layer:

But even weird kernels can lead to surprisingly interesting results. For instance Maximum (dilation filter) that expands the maximum values of a round (or square) region of pixels; resulting in a visually lighter image, we know that the result of the Detail layer application is the opposite: darkened. As follows a 2px radius, with the Detail in Linear Light 50% opacity.

Similarly, the Minimum (erosion) darkens the intermediate hence it’ll lighten the composite:

Speaking of Sharpening, you can get fancy with all sort of Blur kernels (e.g. the ones in the Filters’ Blur Gallery). In the following example I’ve created a new Channel with a gradient that it’s used to apply a Lens Blur filter nicely faded in around the eyes region only. The resulting Detail layer is able to apply a sharpening effect that fades in a way so natural that no layer mask would ever be able to replicate.

6. Multiple Kernels
6.1 Polyfiltered Detail layers
Nothing prevents you from using more than one filter (applied on top of the previous one) to build the layer that will be used to extract the Detail. In the following example I’ve used the Oil Paint filter plus a Smart Blur round.

That still makes a perfectly valid candidate for a two-layers frequency separation that can be used for both retouching or contrast enhancement. Possibilities are endless, provided that you’re able to invent ways to destroy the kind of detail that you want to migrate to a separate layer.
Leaving for the moment the field of perfect decomposition stacks of one base, filtered layer plus the Apply Image on top, there are ways to build interesting Detail layers for contrast enhancement purposes. Later on we’ll learn how to bring them back to decomposition stacks.
6.2 Difference of Gaussians
So far we’ve subtracted a Blurred version from the Original, in order to get the gray-blob that I’ve called the Detail layer. In the case of the Gaussian enhancement, we’ve added the Detail back to the Original (using your preferred blend mode/opacity).
\[D = O - GB\] \[Enhanced = O + D\]The enhancement targets the frequency range from whatever is the Gaussian Blur radius used (in my case 40px) down: so the (0,40)px range4. If you think about GB as a filter that wipes out the higher-than-the-radius frequencies:
\[GB_{(40)} = O_{(40\to\infty)}\]Then you can re-write the equation as:
\[O_{(0\to\infty)} - O_{(40\to\infty)} = D_{(0\to40)}\]That is to say, the Detail layer that contains the frequencies in the range (0,40)px is obtained subtracting an image with frequencies only in the $ (40\to\infty) $ pixels range from the original image that contains all the frequencies.
We’re not limited to use the Original for the subtraction. What if for instance we use two differently blurred images?
\[GB_{(20)} = O_{(20\to\infty)} \\ GB_{(40)} = O_{(40\to\infty)}\] \[O_{(20\to\infty)} - O_{(40\to\infty)} = D_{(20\to40)}\]The result is as follows:

It’s a technique known as Difference of Gaussians, or DoG.

At the moment we’re not yet equipped to use this Detail layer for retouching purposes as well, but I’ll get to that in a short while. Meanwhile, feel free to experiment with different DoG values.
6.3 Edges layer
In the DoG example above we’ve combined two identical (Gaussian) kernels with different parameters. We may now try to combine two different kernels – it’s entirely within the realm of possibilities.
We’ve already met the candidates. Surface Blur (SB) is able to discern the image content, blurring “surfaces” and not “edges”; Gaussian Blur (GB), instead, wipes out everything that is within its frequency range. With a bold leap of faith you can consider the original image (O) to be made of “edges” (E) and “texture” (T): wildly unorthodox math ensues.
\[O = O_T + O_E\] \[SB = O - O_T\] \[GB = O - (O_T + O_E)\] \[SB - GB = (O - O_T) - (O - (O_T + O_E)) = \cancel{O} - \cancel{O_T} - \cancel{O} + \cancel{O_T} + O_E = O_E\]In other words: if GB subtracts both texture plus edges, and SF subtracts texture only, then if you subtract SB from GB you get a Detail layer that contains Edges only without texture. An image might help demonstrating the concept.

This Detail layer has been built with Surface Blur (Radius 12px, Threshold 15px) and Gaussian Blur (radius 10px). The intuition is always the same: how are the two operands different? That difference is what will be enhanced.

Here both textures are more or less blurred the same way: they aren’t different hence they’ll stay the same. Edges (the broad strokes that draw the main traits such as eyes, nose, mouth and hair) are instead dramatically different, hence they’ll get enhanced.
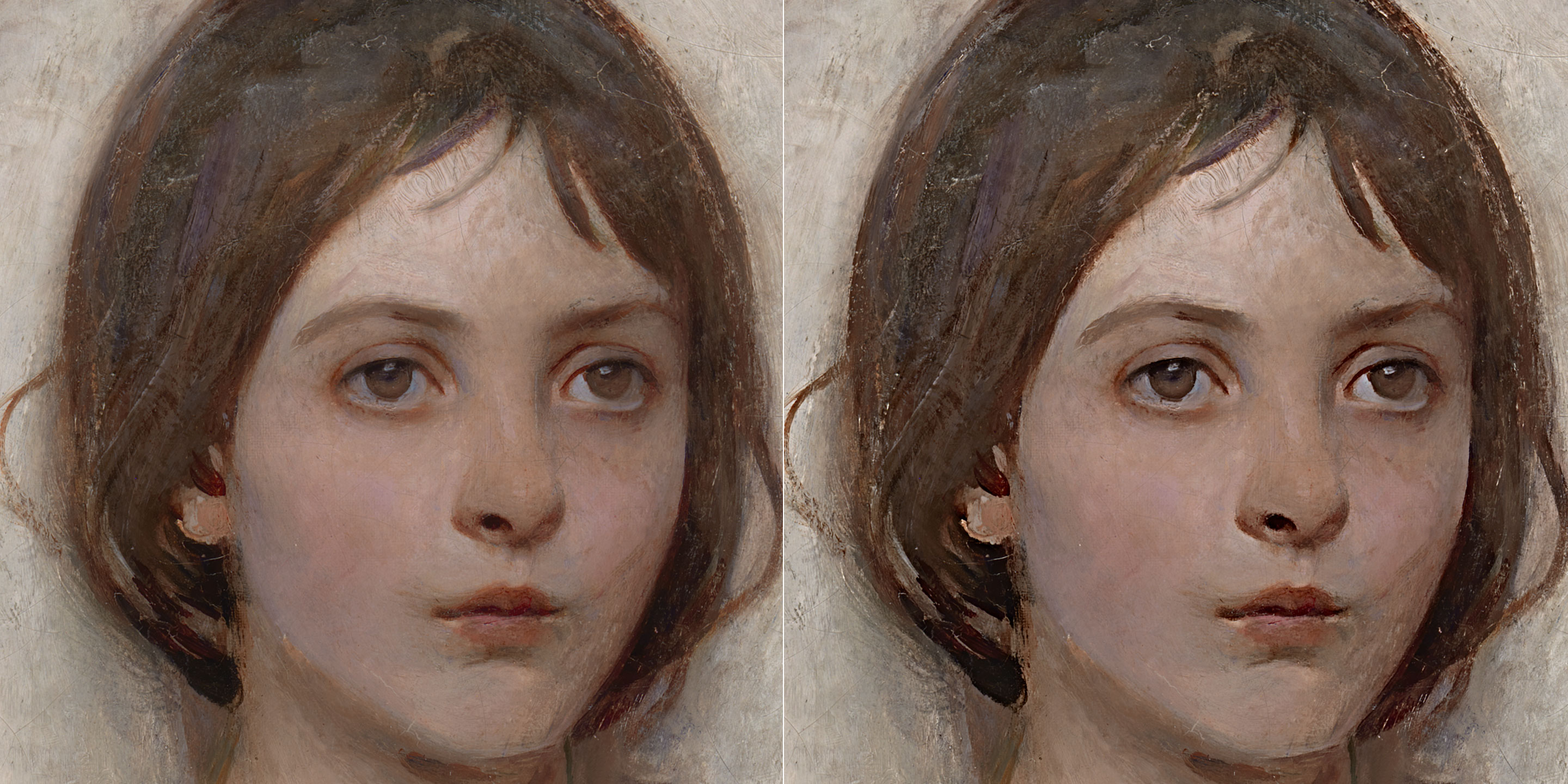
7. Image decomposition
So far we have either performed frequency separations to rebuild a clone of the original image split in two layers (a filtered one, e.g. blurred, plus a difference e.g. the detail in Linear Light blend mode) or we’ve create a variety of independent detail layers for contrast enhancing purposes. It’s time to join the two worlds.
7.1 Gaussian pyramid
Let’s start with the familiar Gaussian kernel. If you recall, with the DoG we’ve targeted very specific frequency ranges, eg. from 40px to 20px. It’s possible to build a pyramid (i.e. a multi-frequency decomposition) splitting the image into more than two layers, e.g. four. These four layers will describe and represent the original image as a sum of four frequency ranges: from “infinity” to 40px; from 40px to 15px; from 15px to 5px; from 5px to zero.
The math is quite straightforward. Let’s call O the Original picture as usual, $ GB_{(n)} $ the GB filter applied with radius $ n $. We need four layers:
\[O, GB_{(5)}, GB_{(15)}, GB_{(40)}\]Let’s define differences Dn as follows:
\[D_1 = O - GB_{(5)} \\ D_2 = GB_{(5)} – GB_{(15)} \\ D_3 = GB_{(15)} - GB_{(40)}\]So the image can be decomposed into:
\[O = GB_{(40)} + D_1 + D_2 + D_3\]In fact, substituting all the elements we get:
\[O = \cancel{GB_{(40)}} + O - \cancel{GB_{(5)}} + \cancel{GB_{(5)}} - \cancel{GB_{(15)}} + \cancel{GB_{(15)}} - \cancel{GB_{(40)}} = O\]Everything simplifies and we’re left with the same original image. Let’s switch to Photoshop and try to build this pyramid: first thing, we need the original plus three progressively more blurred layers.

Second, we need the $ GB_{(40)} $ and $ D_1, D_2, D_3 $. These are just Difference of Gaussians, the same DoG we’ve already encountered.

When you have all the ingredients, you can add them together via Linear Light blending.

The result is a pixel perfect copy of the original with all the three Detail ranges exposed: $ (40\to15), (15\to5), (5\to0) $ pixels.
You can now either exploit this frequency separation for retouching purposes, or add each Detail layer back to the original (with various blending modes and/or opacities) for a frequency range targeted contrast boost.
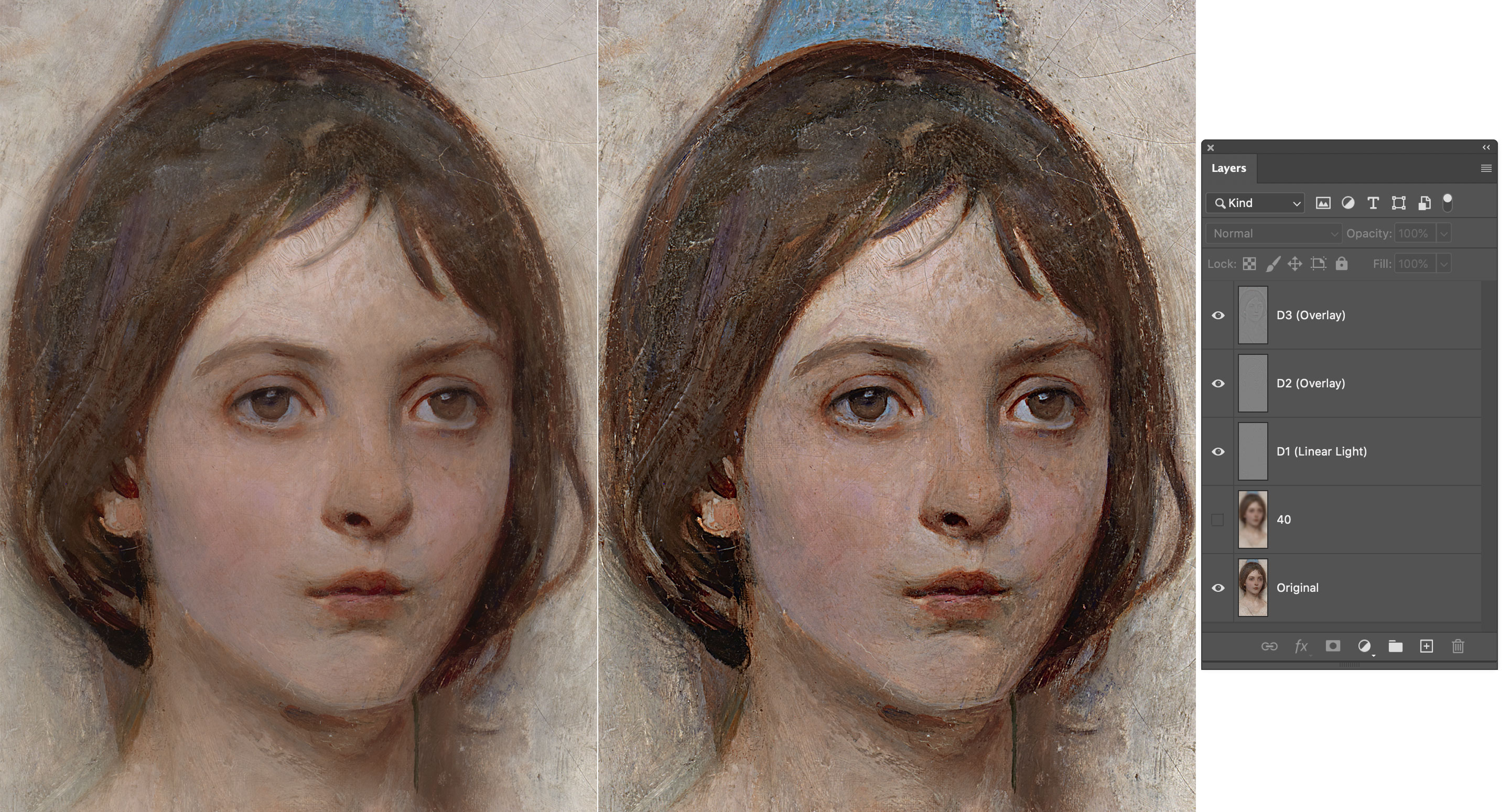
Keep in mind that:
- If instead of boost, you need to decrease the impact of a particular frequency range, do invert the Detail layer.
- The order of the Detail layers in the stack doesn’t really matter, you can freely mix them.
- There’s no limit to the amount of Detail layers you want to create.
- You can always clip a Curves adjustment if you want to perform some peculiar edit to a Detail layer.
7.2 Mixed pyramids
To properly conclude, there’s still one technique that needs to be revisited and incorporated into multi-layer frequency decompositions. If you remember, not long ago we’ve mixed Gaussian and Surface Blur to obtain an “Edges” Detail layer. It may surprise you (or it may not, at this point) to know that you’re not at all forced to use the same kernel in a decomposition: you’re free to use any kernel that make sense. Let’s try to build a GB/SB pyramid!
We need three layers:
\[O, SB_{(12,15)}, GB_{(10)}\]
Let’s define differences Dn as follows:
\[D_1 = O - SB_{(12,15)}\] \[D_2 = SB_{(12,15)} – GB_{(10)}\]So the image can be decomposed into:
\[O = GB_{(10)} + D_1 + D_2\]In fact, substituting all the elements we get:
\[O = \cancel{GB_{(10)}} + O - \cancel{SB_{(12,15)}} + \cancel{SB_{(12,15)}} – \cancel{GB_{(10)}} = O\]
The image can be then recomposed as usual.

The Detail layers can be used for either retouching purposed or contrast enhancement.
The general equations for the decomposition are:
\[U_0 = O \\ U_1 = Filter_1(O) \\ U_2 = Filter_2(O) \\ \cdots \\ U_{n-1} = Filter_{n-1}(O) \\ U_n = Filter_n(O)\] \[D_1 = U_0 – U_1 \\ D_2 = U_1 – U_2 \\ \cdots \\ D_{n-1} = U_{n-2} – U_{n-1} \\ D_n = U_{n-1} – U_n\] \[O = U_n + D_1 + D_2 + \cdots + D_{n-1} + D_n\]At this point it’s up to you to decide which kernels to mix, and for which goal. Always remember to look for filters and filter combinations/subtractions that affects the feature you’re interested into – imagination can fly high!

References
- Abbott Handerson Thayer, a portrait of his daughter from the Smithsonian Institute collection, 1887.
- The Ultimate Guide To The Frequency Separation Technique by Julia Kuzmenko McKim is a nice introductory guide to simple 2-layers decompositions.
- Former Adobe’s Imaging Senior Engineer Chris Cox about the decision to use 15bit + 1.
- As for why Linear Light Blend uses 256 as a white point, see here.
- Blend modes info are found everywhere but with various degree of precision. I’ve used
Wikipedia of course, PhotoBlogStop, but the most interesting have been Murphy Chen (Chinese language) and Pegtop. - If you’re curious, my 2009 original article can still be found here.
- All illustrations are mine. Blend mode graphs are plotted with p5.js.
-
I take in consideration one channel only for simplicity’s sake. ↩
-
HardLight has the same formula than Overlay, but it uses the upper layer to determine which formula to apply (Overlay uses the layer below instead). ↩
-
I keep using “subtract” as a verb, but you should use the more appropriate Apply Image to the document’s bit depth. ↩
-
It’s a bit counter-intuitive at first, because “down” in this case means to higher frequencies. ↩